¶ Announcement: Retirement of Readarr
We would like to announce that the Readarr project has been retired. This difficult decision was made due to a combination of factors: the project's metadata has become unusable, we no longer have the time to remake or repair it, and the community effort to transition to using Open Library as the source has stalled without much progress.
Third-party metadata mirrors exist, but as we're not involved with them at all, we cannot provide support for them. Use of them is entirely at your own risk. The most popular mirror appears to be rreading-glasses.
Without anyone to take over Readarr development, we expect it to wither away, so we still encourage you to seek alternatives to Readarr.
¶ Key Points
- Effective Immediately: The retirement takes effect immediately. Please stay tuned for any possible further communications.
- Support Window: We will provide support during a brief transition period to help with troubleshooting non metadata related issues.
- Alternative Solutions: Users are encouraged to explore and adopt any other possible solutions as alternatives to Readarr.
- Opportunities for Revival: We are open to someone taking over and revitalizing the project. If you are interested, please get in touch.
- Gratitude: We extend our deepest gratitude to all the contributors and community members who supported Readarr over the years.
Thank you for being part of the Readarr journey. For any inquiries or assistance during this transition, please contact our team.
Sincerely,
The Servarr Team
¶ Table of Contents
- Table of Contents
- Menu options
- Media Management
- Permissions
- Profiles
- Quality
- Indexers
- Download Clients
- Import Lists
- Connect
- Metadata
- Tags
- General
- UI (User Interface)
This page will go through all the settings available in Readarr and how they work. This is not meant to be a comprehensive "how to set up Readarr." If you want that, please use the Quick Start page instead.
¶ Menu options
To get to the Settings page, please choose Settings from the left menu. The following sub-menu options will be available:

Also, note that for each individual settings page, there are some options at the top of the menu:

-
Hide/Show advanced is important for any items that are marked below as
(Advanced Option), otherwise they will not show up. These menu items are shown in orange in the screenshots. -
You must save your changes before leaving the screen. You do that by clicking the disk icon. If you've made no changes, it will show "No Changes" and be grayed out, as shown above.
¶ Media Management
Some of these settings are only visible through
Show Advanced Settingswhich is on the top bar under the search bar
¶ Root Folders
- A list of your configured Root Folders (Library Folders) is displayed.
- Click the + button to add a new Root Folder or click an existing's card to edit it.
¶ Root Folder Settings
- Name - The name of the Root Folder for UI Purposes
- Path - The folder containing your book library i.e. the final destination as Readarr sees it.
- Note that this must be different than the location your download client places files.
- If you are using docker and Calibre integration, the mounts must be the same to your books folder.
- Calibre Specific Settings (Only if Use Calibre is enabled)
- Use Calibre - Enable / Disable the use of Calibre Content Server to manage your Root Folder.
* Only for use with ebooks, not audiobooks!
* Note that this cannot be enabled on an existing root folder.
* Note that this cannot be disabled on an existing Calibre enabled root folder.
* Note that this requires Calibre Content Server and will not work with Calibre Web nor Calibre.
* Note that hard links do not work with Calibre integration.
* Note that this requires that Calibre to haveRequire username and password to access the content serverto be enabled.
* Failure to haveRequire username and password to access the content serverenabled in Calibre will result in an error ofAnonymous users are not allowed to make changes
- Calibre Host - The IP/domain of the host of the Calibre Content Server
- Calibre Port - The Port that Calibre Content Server is listening on
- (Advanced) Calibre URL Base - Add a prefix to the Calibre URL e.g.
http://[host]:[port]/[urlBase] - Calibre Username - Username to use to access Calibre Content Server
- Calibre Password - Password to use to access Calibre Content Server
- Calibre Library - Calibre Content Server library name. Leave blank for default
- Convert to Format - (Optional) Ask Calibre Content Server to convert to other formats with a comma separated list.
- Review the (i) icon within the app for a current list of options.
- Options are: MOBI, EPUB, AZW3, DOCX, FB2, HTMLZ, LIT, LRF, PDB, PDF, PMLZ, RB, RTF, SNB, TCR, TXT, TXTZ, ZIP
- Calibre Output Profile - Select the Calibre Content Server Output Profile to use
- The output profile tells the Calibre Content Server conversion system how to optimize the created document for the specified device (such as by resizing images for the device screen size). In some cases, an output profile can be used to optimize the output for a particular device, but this is rarely necessary.
- Use SSL - Enable or Disable the use of SSL (HTTPS) for Calibre Content Server
- Monitor - Configure your monitoring options for books detected in this folder
- All Books - Monitor all books
- Future Books - Monitor books that have not released yet
- Missing Books - Monitor books that do not have files or have not released yet
- Existing Books - Monitor books that have files or have not released yet
- First Book - Monitor the first book. All other books will be ignored
- Latest Book - Monitor the latest book and future books
- None - No books will be monitored unless explicitly added
- Quality Profile - Default Quality Profile for books and authors detected within this folder
- Metadata Profile - Select the Metadata Profile to use for authors detected in this folder. To only load books that were explicitly added or detected select None.
- Default Readarr Tags - Default tags for authors detected within this folder
Non-Windows Users:
* If you're using an NFS mount ensurenolockis enabled.
* If you're using an SMB mount ensurenobrlis enabled.
¶ Remote Path Mappings
- Remote Path Mapping acts as a dumb find Remote Path and replace with Local Path This is primarily used for either merged local/remote setups using mergerfs or similar or is used for when the application and download client or Calibre are not on the same server.
- For more information see the section in Download Clients => Remote Path Mapping replace
<Download Client>with<Calibre>
¶ Book File Naming
If you are using Calibre integration, you do not get to name book files. Calibre takes care of this for you. You should only change these settings if you are not using Calibre.
Please note that while Readarr is in beta; if you use Calibre it is recommended to disable Renaming in Readarr just in case an unintended bug slips through. `
Commonly used naming schema are:
-
Standard Book Format
{Book Title}\{Author Name}-{Book Title}which would then output a folder namedCujo, and a subdirectory containing a file with the nameStephen King - Cujo.m4b
-
Author Folder Format
{Author Name}which would then output:Stephen King
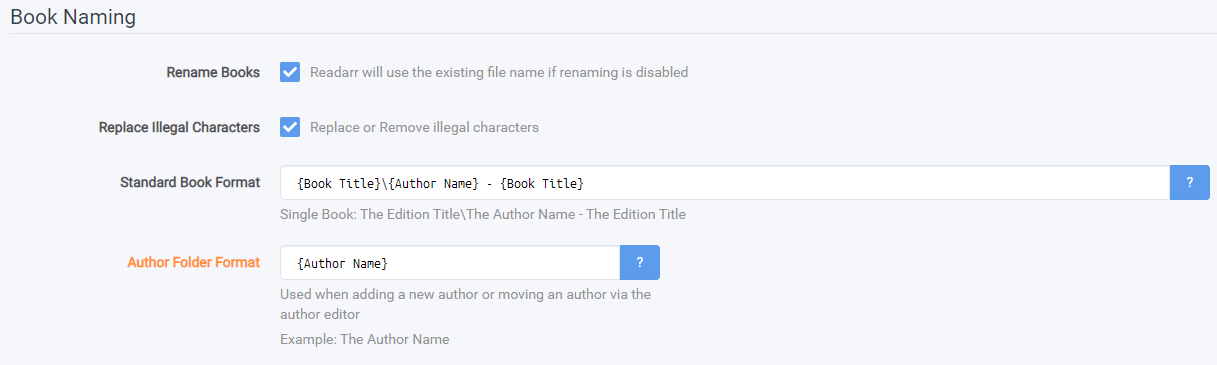
¶ Book Naming
- Rename Books - If this is toggled off (no check in the box) Readarr will use the existing file name if renaming is disabled.
- If unchecked:
- Download Client Import
- Download Client's Release Title is used
- Manual (Ad-Hoc) Import: Original File Name
- Download Client Import
- If unchecked:
If you leave Rename Books unchecked, then none of the naming below applies - you have told Readarr you do not want any renaming done at all. The book will be imported directly into the author folder.
This does not apply if Calibre is used as Calibre handles file/folder naming using its own internal schema.
- Replace Illegal Characters - If disabled Readarr will remove illegal characters. If enabled Readarr will replace illegal characters. Examples include
\ # / $ * < >and more.
¶ Standard Book Format
-
Select the naming
-
Dropdown Box (upper right corner)
- Left Box - Space Handling
Space ( )- Use spaces in naming (Default)Period (.)- Use periods in lieu of spaces in namingUnderscore (_)- Use underscores in lieu of spaces in namingDash (-)- Use dashes in lieu of spaces in naming
- Right Box - Case Handling
Default Case- Make title uppercase and lowercase (~camel-case) (Default)Uppercase- Make title all uppercaseLowercase- Make title all lowercase
- Left Box - Space Handling
¶ Author
{Author Name}= Author's Name{Author NameThe}= Author's Name, The{Author CleanName}= Authors Name{Author SortName}= Name, Author{Author Disambiguation}= Author Name (disambiguation used from GoodReads for multiple authors with the same name)
¶ Book
{Book Title}= The Book's Title!: Subtitle!{Book TitleThe}= Book's Title!, The: Subtitle!{Book CleanTitle}= The Books Title: Subtitle{Book TitleNoSub}= The Book's Title!{Book TitleTheNoSub}= Book's Title!, The{Book CleanTitleNoSub}= The Books Title{Book Subtitle}= Subtitle!{Book SubtitleThe}Subtitle!, The{Book CleanSubtitle}= Subtitle{Book Disambiguation}= Book Name! (disambiguation title used from GoodReads){Book Series}= Series Title{Book SeriesPosition}= 1{Book SeriesTitle}= Series Title #1{PartNumber:0}or{PartNumber:0}= 2{PartNumber:00}= 02{PartCount}or `{PartCount:0} = 9{PartCount:00}= 09
¶ Release Date
{Release Year}= 2016{Release YearFirst}= 2015{Edition Year}= 2016
¶ Quality
{Quality Full}= AZW3 Proper{Quality Title}= AZW3
¶ Media Info
{MediaInfo AudioCodec}= MP3{MediaInfo AudioChannels}= 2.0{MediaInfo AudioBitRate}= 320kbps{MediaInfo AudioBitsPerSample}= 24bit{MediaInfo AudioSampleRate}= 44.1kHz
¶ Other
{Release Group}= Rls Grp{Preferred Words}= iNTERNAL
¶ Original
{Original Title}= Author.Name.Book.Name.2018.AZW3-EVOLVE{Original Filename}= 01-book name
Original Filename is not recommended. It is the literal original filename and may be obfuscated t1i0p3s7i8yuti. Original Title is the release name and should be used instead.
¶ Author Folder Format
- (Advanced Option) This is where you will set the naming convention for the author folder name.
This does not apply if Calibre is used as Calibre handles file/folder naming using its own internal schema.
¶ Author
{Author Name}= Author's Name{Author NameThe}= Author's Name, The{Author CleanName}= Authors Name{Author SortName}= Name, Author{Author Disambiguation}= Author Name (disambiguation used from GoodReads for multiple authors with the same name)
¶ Folders

- (Advanced Option) Create empty author folders - Select the box to create empty author folders when a new author is added.
- (Advanced Option) Delete empty author folders - Select the box to delete empty author folders if there are no books in it.
One of those boxes can be checked, but they should not BOTH be checked.
This does not apply if Calibre is used as Calibre handles file/folder naming using its own internal schema.
¶ Importing
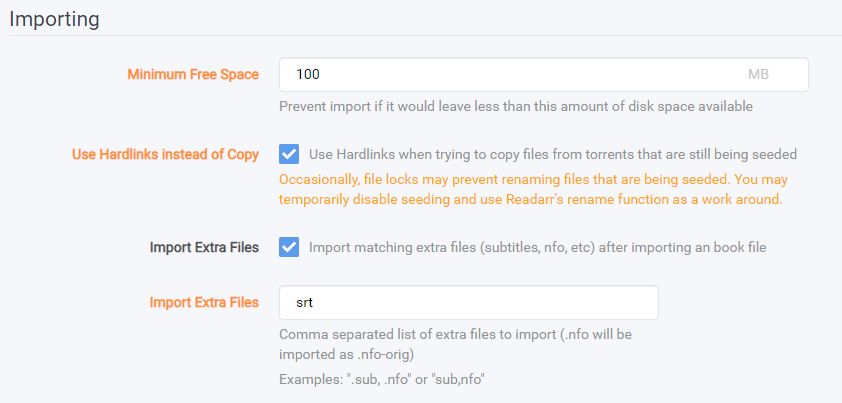
- (Advanced Option) Skip Free Space Check - If enabled skip checking free space prior to importing
- (Advanced Option) Minimum Free Space - Enter the minimum free space for the drive to have before importing stops.
- (Advanced Option) Use Hard links instead of Copy - Check this box to use Hard links instead of Copies (for Torrents). Note that this is enabled by default.
You should ideally use this wherever possible. In order for hard links to be used, you must have your source/destination on the same file system (drive, partition) and mount points. See TRaSH's Hardlink Guide for more information
- Import Extra Files - If enabled import specified extra files located within the folder of the book when its imported
- (Advanced Option) Import Extra Files - If Import Extra Files is enabled enter a comma separated list of extensions to import.
If you are using Readarr for audiobooks, you should add .cue to this list, as it holds your chapter information!
¶ File Management
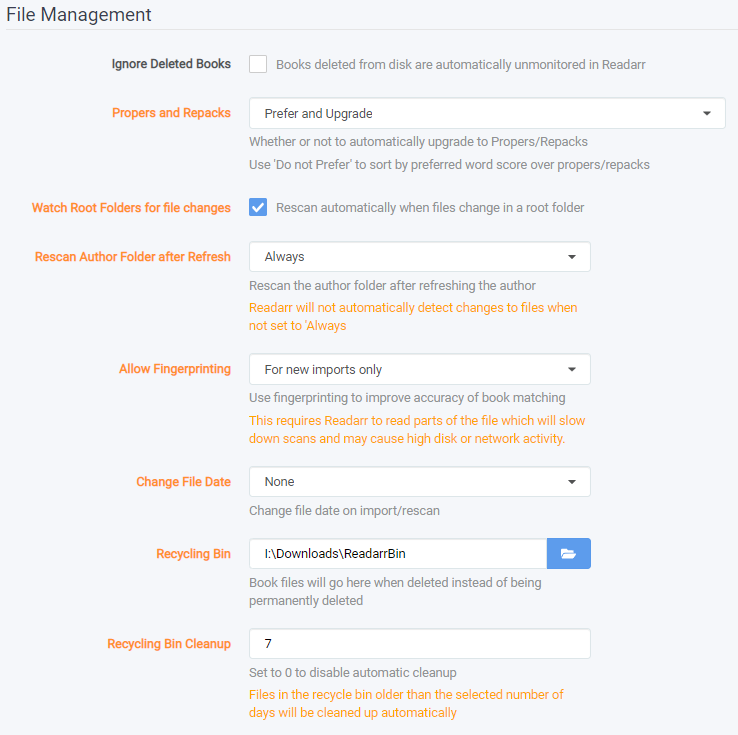
- Ignore Deleted Books - Check this box to unmonitor books detected as deleted or inaccessible from Readarr's root folder.
- Download Proper & Repacks - Whether or not to automatically upgrade to Propers/Repacks. Use
Do not Preferto sort by preferred word score over propers/repacks- Prefer and Upgrade - Rank repacks and propers higher than non-repacks and non-propers. Treat new repacks and propers as upgrade to current releases.
- Do Not Upgrade Automatically - Rank repacks and propers higher than non-repacks and non-propers. Do not treat new repacks and propers as upgrade to current releases.
- Do Not Prefer - Effectively this ignores repacks and propers. You'll need to manage any preference for those with Preferred Words.
*
PROPER- means there was a problem with the previous release. Downloads tagged as PROPER shows that the problems have been fixed in that release. This is done by a Group that did not release the original.
*REPACK- means there was a problem with the previous release and is corrected by the original Group. Downloads tagged as REPACK shows that the problems have been fixed in that release. This is done by a Group that did release the original.
- (Advanced Option) Watch Root Folders for file changes - Check this box to trigger a rescan when it is detected that the root folder had changes.
- (Advanced Option) Rescan Author Folder after Refresh - Choose when to rescan an author folder after refreshing the author.
- Always - This will rescan author folders based upon Tasks Schedule
- After Manual Refresh - You will have to manually rescan the disk
- Never - Just as it says, never rescan the author folders.
- (Advanced Option) Allow Fingerprinting - Choose how to handle fingerprinting, which allows increased accuracy for book matching, at the expense of CPU/disk time.
- Always - Always use fingerprinting if possible
- For new imports only - Only fingerprint newly imported releases
- Never - Just as it says, never use fingerprinting
- (Advanced Option) Change File Date - Change file date on import/rescan
- None - Readarr will not change the date that shows in your given file browser
- Book Release Date - The date the book was released.
- (Advanced Option) Recycling Bin - Book files will go here when deleted instead of being permanently deleted
- (Advanced Option) Recycling Bin Cleanup - This is how old a given file can be before it is deleted permanently
It is highly recommended that you use a Recycling Bin. It's easy to delete files, and recovering them is easy if you use the bin.
¶ Permissions
- Set Permissions - Should
chmodbe run when files are imported/renamed?- chmod Folder - Octal, applied during import/rename to media folders and files (without execute bits)
The drop down box has a preset list of very commonly used permissions that can be used. However, you can manually enter a folder octal if you wish.
This only works if the user running
Readarris the owner of the file. It's better to ensure the download client sets the permissions properly.
- chown Group - Group name or GID. Use GID for remote file systems
This only works if the user running
Readarris the owner of the file. It's better to ensure the download client sets the permissions properly.
¶ Profiles
¶ Quality Profiles
Quality profiles are used to determine what formats of books are acceptable for a book in your library.
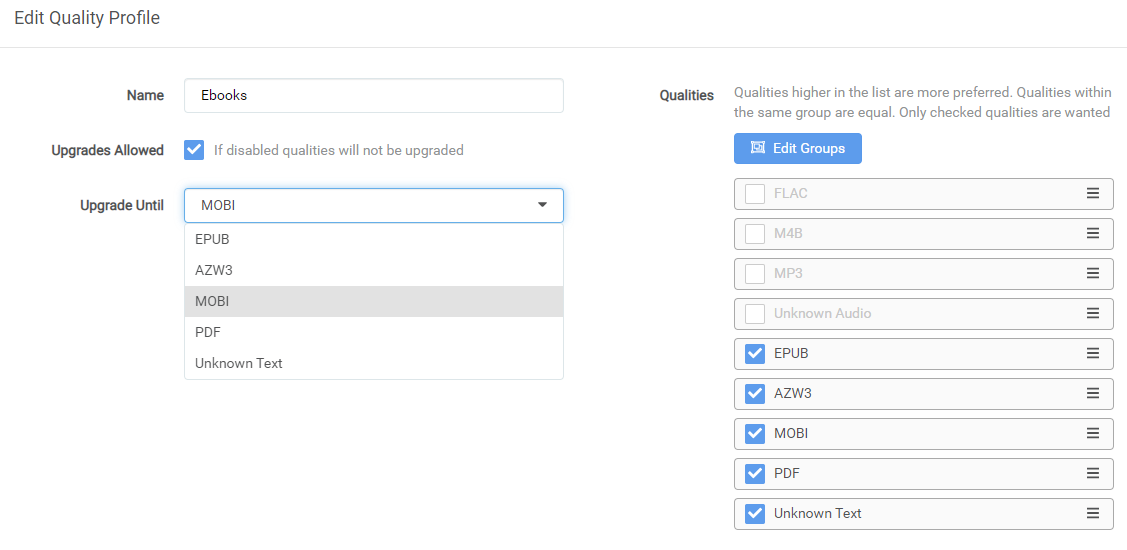
- Set profiles for the quality of books you're looking to download.
When selecting an existing profile or adding an additional profile a new window will appear
Note: The quality which has a blue box is the quality at which any media with this profile will continue to be upgraded to.
-
Plus icon (+) - Create a new quality profile
-
Name - Enter a UNIQUE name for the quality profile you are creating
-
Upgrades Allowed - When this option is checked and you tell Readarr to download a
EPUBas it is the first release of a specific book then later somebody is able to upload aAZW3Readarr will automatically upgrade to the better quality ifUpgrade Untilhas that quality selected- Upgrade Until - Once this quality is reached Readarr will no longer download movies
Note: This is only applicable if you have
AZW3higher thanEPUBwithin theQualitiessection
- Qualities - Qualities higher in the list are more preferred regardless of wanted (enabled/checked) status. for ranking regardless of enabled status. Qualities within the same group are equal. Only checked (enabled) qualities are wanted (allowed)
-
Edit Groups - Some qualities are grouped together to reduce the size of the list as well grouping like releases. Prime example of this is
WebDLandWebRipas these are very similar and typically have similar bitrates. When editing the groups you can change the preference within each of the groups.
-
By default the qualities are set from "worst" (bottom) to "best" (top)
¶ Metadata Profiles
Metadata profiles are used to determine which books from GoodReads to add under an author when a new author is added.
- Plus icon (+) - Create a new Metadata profile
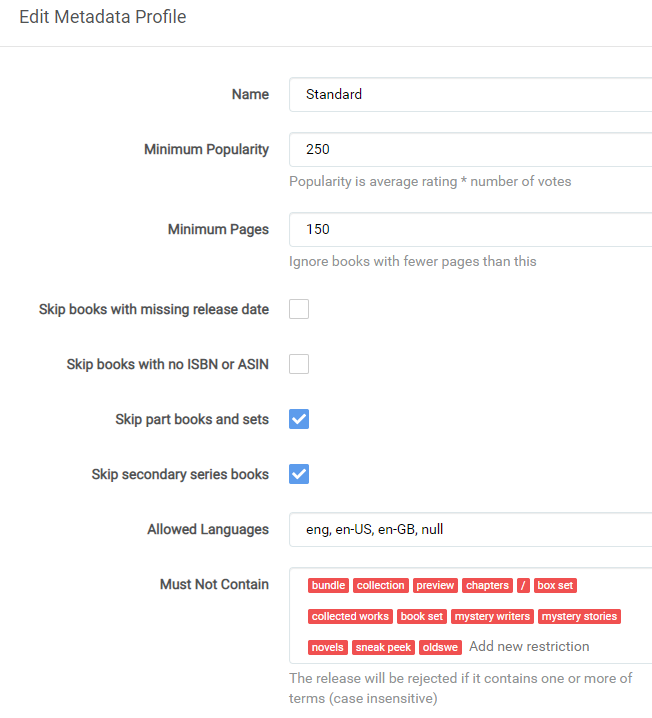
- Name - Enter a UNIQUE name for the metadata profile profile
- Minimum Popularity - Enter the minimum popularity for a book to be added for an author.
Setting this too high will result in books not being added to Readarr, but setting it too low will result in obscure publications showing up.
Set this to
10000000000exactly to create a profile equivalent toNonebut still allow other filtering of editions and books. Note thatNonedoes not apply any metadata filters and you may get foreign editions.
- Minimum Pages - Enter the minimum number of pages a book must have to be added for an author.
- Skip books with missing release date - Enable to skip books with a missing release date.
- Skip books with no ISBN or ASIN - Enable to skip books that do not contain either an ISBN or ASIN number.
- Skip part books and sets - Enable to skip part books and sets.
- Skip secondary series books - Enable to skip secondary series books.
- Allowed Languages - Enter a comma-separated list of ISO 639-3 language codes, or 'null' for allowable languages for your books
- Must Not Contain - Enter words or phrases that a book title must not contain in order to be added.
You may create multiple metadata profiles, and apply a separate one to each author as needed. But, you may only apply a single metadata profile to any given author.
¶ Release Profiles
Release profiles are used to determine if indexer release names qualify for downloading.
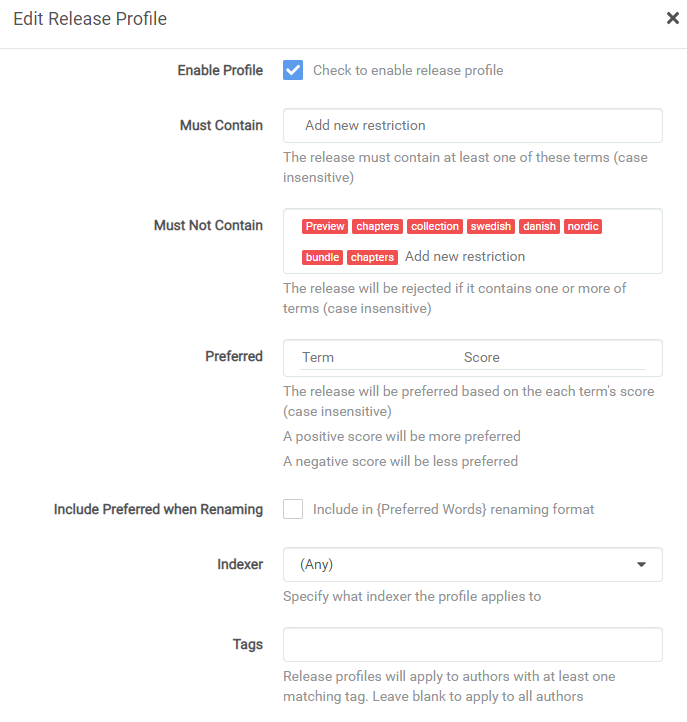
- Enable Profile - Check the box to enable this profile.
- Must Contain - Add a list of words or phrases that MUST be in the release name in order to be considered valid.
- Must Not Contain - Add a list of words or phrases that MUST NOT be in the release name in order to be considered valid.
- Preferred (Words) - Here you can add terms or regex with scores (positive and negative) to be considered more or less preferable. For example, you may prefer "unabridged" with a positive score.
Releases with a higher preferred word score than the existing file are ALWAYS an upgrade!
- Include Preferred when Renaming Check this box to include your preferred words (or regex matches) in the
{Preferred Words}file naming assignment token.
You should include
{Preferred Words}in your file naming, and check this box if you're using them, because otherwise you can end up in a download loop.
- Indexer - In this drop-down, you can limit this release profile to a single indexer. This should almost always be left at
(any) - Tags - Enter a tag here, to be able to apply this tag to authors with the same tag. If you do not apply a tag here, then this profile applies to ALL authors.
¶ Delay Profiles
- Delay profiles allow you to reduce the number of releases that will be downloaded for an book by adding a delay while Readarr continues to watch for releases that better match your preferences.
- Protocol - This will either be
UsenetorTorrentdepending on which download protocol you prefer - Usenet Delay - Set by the number of minutes you will want to wait before the download to start
- Torrent Delay - Set by the number of minutes you will want to wait before the download to start
- Bypass if Highest Quality - Bypass delay when release has the highest enabled quality profile with the preferred protocol
- Tags - With giving this delay profile a tag you will be able to tag a given movie to have it play by the rules set here.
- Wrench icon - This will allow you to edit the delay profile
- Plus icon (+) - Create a new delay profile
¶ Uses
Some media will receive half a dozen different releases of varying quality in the hours after a release, and without delay profiles Readarr might try to download all of them. With delay profiles, Readarr can be configured to ignore the first few hours of releases.
Delay profiles are also helpful if you want to emphasize one protocol (Usenet or BitTorrent) over the other. (See Example 3)
¶ How Delay Profiles Work
The timer begins as soon as Readarr detects a books has a release available. This release will show up in your Queue with a clock icon to indicate that it is under a delay.
The clock starts from the releases uploaded time and not from the time Readarr sees it.
During the delay period, any new releases that become available will be noted by Readarr. When the delay timer expires, Readarr will download the single release which best matches your quality preferences.
The timer period can be different for Usenet and Torrents. Each profile can be associated with one or more tags to allow you to customize which shows have which profiles. A delay profile with no tag is considered the default and applies to all shows that do not have a specific tag.
Delay profiles start from the time stamp that the indexer reports the release was uploaded. This means that any content older than the number of minutes you have set are not impacted in any way by your delay profile, and will be downloaded immediately. In addition, any manual searches for content (non-RSS feed searches) will ignore delay profile settings.
¶ Examples
- For each example, assume the user has the follow quality profile active: EPUB and above are allowed MOBI is the quality cutoff * AZW3 is the highest ranked quality
¶ Example 1
-
In this simple example, the profile is set with a 120 minute (two hour) delay for both Usenet and Torrent.
-
At 11:00pm the first release for an books is detected by Readarr and it was uploaded at 10:50pm and the 120 minute clock begins. At 12:50am, Readarr will evaluate any releases it has found in the past two hours, and download the best one, which is MOBI.
-
At 3:00am another release is found, which is MOBI that was added to your indexer at 2:46am. Another 120 minute clock begins. At 4:46am the best-available release is downloaded. Since the quality cutoff is now reached, the books no longer is upgradeable and Readarr will stop looking for new releases.
-
At any point, if a AZW3 release is found, it will be downloaded immediately because it is the highest-ranking quality. If there is a delay timer currently active it will be canceled.
¶ Example 2
-
This example has different timers for Usenet and Torrents. Assume a 120 minute timer for Usenet and a 180 minute timer for BitTorrent.
-
At 11:00pm the first release for an books is detected by Readarr and both timers begin. The release was added to the indexer at 10:15pm At 12:15am, Readarr will evaluate any releases, and if there are any acceptable Usenet releases, the best one will be downloaded and both timers will end. If not, Readarr will wait until 12:15am and download the best release, regardless of which source it came from.
¶ Example 3
-
A common use for delay profiles is to emphasize one protocol over another. For example, you might only want to download a BitTorrent release if nothing has been uploaded to Usenet after a certain amount of time.
-
You could set a 60 minute timer for BitTorrent, and a 0 minute timer for Usenet.
-
If the first release that is detected is from Usenet, Readarr will download it immediately.
-
If the first release is from BitTorrent, Readarr will set a 60 minute timer. If any qualifying Usenet release is detected during that timer, the BitTorrent release will be ignored and the Usenet release will be grabbed.
¶ Quality
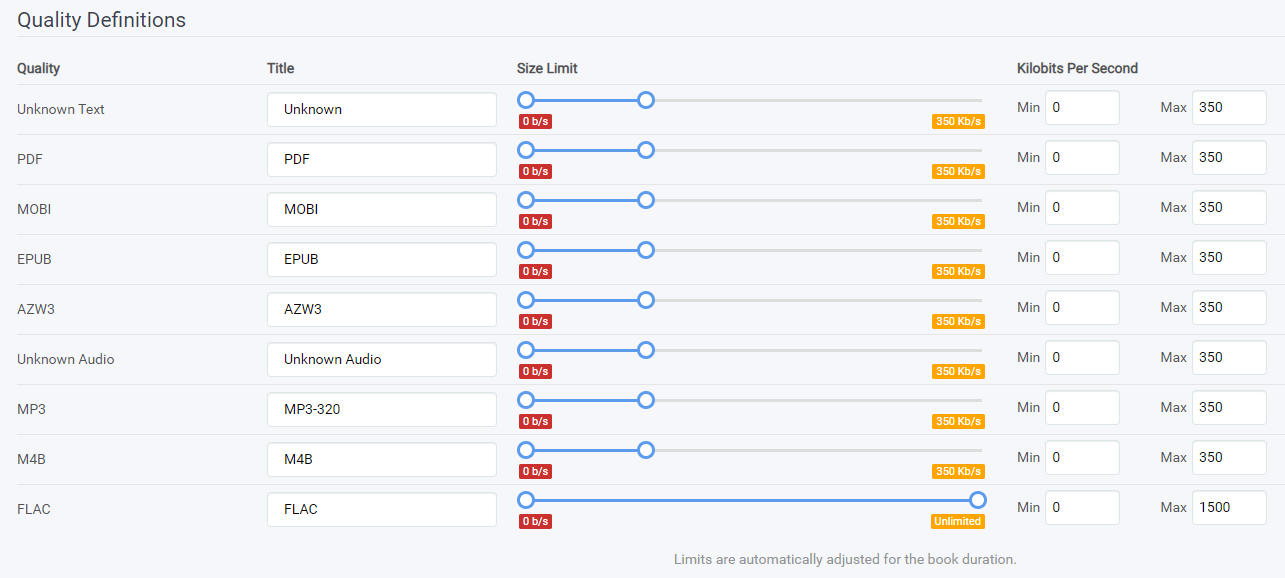
¶ Quality Table Meanings
- Quality - The scene quality name (hardcoded)
- Title - The name of the Quality in the GUI (configurable)
- Megabytes Per Minute - Self Explanatory
- Size Limit - Self Explanatory
- Min - The minimum Bytes or Kilobytes per Second (b/s|kb/s) a quality can have.
- Max - The maximum Bytes or Kilobytes per Second (b/s|kb/s) a quality can have.
¶ Qualities Defined
- Unknown Text - Self Explanatory
- PDF - Portable Document File
- MOBI - One of the most widely used ebook file formats
- EPUB - Another one of the most widely used ebook file formats
- AZW3 - AZW3 is an eBook file that is developed by Amazon. It is used in Amazon Kindles to view eBooks.
- Unknown Audio - Self Explanatory
- MP3 - Common lossy Audio format
- M4B - Common audiobook file format
- FLAC - Free Lossless Audio Codec, an audio format similar to MP3, but lossless
¶ Indexers
Information on supported indexers can be found at the More Info (Supported) page for this section
¶ Supported Indexers
- A list of supported indexers is located at the More Info (Supported) page
¶ Indexer Settings
-
Once you've clicked the + button to add a new indexer you will be presented with a new window with many different options. For the purposes of this wiki Readarr considers both Usenet Indexers and Torrent Trackers to be "Indexers".
-
There are two sections here: Usenet and Torrents. Based upon what download client you will be using you will want to select the type of indexer you will be going with.
¶ Usenet Indexer Configuration
- Newznab - Here you will find presets of popular usenet indexers (that are prefilled out, all you will need is your API key which is provided by the usenet indexer of your choice) along with the ability to create a custom Indexer
- Software that works with usenet and integrates quite well with Readarr are NZBHydra2 or Prowlarr which integrate with both Usenet and Torrents
- Regardless if you select a prefilled out indexer or a custom indexer setup you will be presented with a new window to input all your settings
- Choose from the presets or add a custom indexer (such as NZBHydra2 or Prowlarr)
- Name - The name of the indexer in Readarr
- Enable RSS - If enabled, use this indexer to watch for files that are wanted and missing or have not yet reached their cutoff.
- Enable Automatic Search - If enabled, use this indexer for automatic searches including Search on Add
- Enable Interactive Search - If enabled, use this indexer for manual interactive searches.
- URL - The indexer provided URL of the indexer such as
https://api.nzbgeek.info. - API Path - The indexer provided path to the api. This is typically
/api - Multi Languages - Set what languages
MULTIare for this indexer. - API Key - The indexer provided key to access the API.
- Categories - Default categories will be used unless edited. It is likely these default categories are suboptimal. Upon editing this setting, Readarr queries the indexer for its available categories and displays them in a selectable a list. The stale defaults will clear as soon as a category is toggled.
- (Advanced Option) Early Download Limit - Time before release date Readarr will download from this indexer, leave blank for no limit. This is similar to availability in Radarr.
- (Advanced Option) Additional Parameters - Additional Newznab parameters to add to the query link
- (Advanced Option) Indexer Priority - Priority of this indexer to prefer one indexer over another in release tiebreaker scenarios. 1 is highest priority and 50 is lowest priority.
¶ Torrent Tracker Configuration
- As with Usenet there are an assortment of prefilled out Torrent tracker information. If you are not a member of any of these these specific trackers they will not do you any good.
- One of the simplest ways to utilize Torrent trackers with Readarr is by using a second program such as Prowlarr or Jackett. These software pair well with Readarr and act as a search indexer that houses all your information and sends it to Readarr.
- Torznab - This option will set you up with a Jackett preset, if you utilize multiple trackers you will need to have each entry have a unique name
- Torznab Indexer
- Choose from the presets or add a custom indexer (such as Jackett)
- Name - The name of the indexer in Readarr
- Enable RSS - If enabled, use this indexer to watch for files that are wanted and missing or have not yet reached their cutoff.
- Enable Automatic Search - If enabled, use this indexer for automatic searches including Search on Add
- Enable Interactive Search - If enabled, use this indexer for manual interactive searches.
- URL - The indexer provided URL such as
http://localhost:9117/jackett/api/v2.0/indexers/torrentdb/results/torznab/. - API Path - The indexer provided path to the api. This is typically
/api - API Key - The indexer provided key to access the API.
- Multi Languages - Set what languages
MULTIare for this indexer. - Categories - Default categories will be used unless edited. It is likely these default categories are suboptimal. Upon editing this setting, Readarr queries the indexer for its available categories and displays them in a selectable a list. The stale defaults will clear as soon as a category is toggled.
- (Advanced Option) Early Download Limit - Time before release date Readarr will download from this indexer, leave blank for no limit. This is similar to availability in Radarr.
- (Advanced Option) Additional Parameters - Additional Newznab parameters to add to the query link
- (Advanced Option) Indexer Priority - Priority of this indexer to prefer one indexer over another in release tiebreaker scenarios. 1 is highest priority and 50 is lowest priority.
- (Advanced Option) Minimum Seeders - The minimum number of seeders required for a release from this tracker to be grabbed.
- (Advanced Option) Seed Ratio - If empty, use the download client default. Otherwise, the minimum seed ratio required for your download client to meet for releases from this indexer prior to it being paused by your client and removed by Readarr (Requires Completed Download Handling - Remove enabled)
- (Advanced Option) Seed Time - If empty, use the download client default. Otherwise, the minimum seed time in minutes required for your download client to meet for releases from this indexer prior to it being paused by your client and removed by Readarr (Requires Completed Download Handling - Remove enabled)
- (Advanced Option) Discography Seed Time - Ignore, carry over from Lidarr
- (Advanced Option) Indexer Priority - Priority of this indexer to prefer one indexer over another in release tiebreaker scenarios. 1 is highest priority and 50 is lowest priority.
¶ Options
- Minimum Age - Usenet only: Minimum age in minutes of NZBs before they are grabbed. Use this to give new releases time to propagate to your usenet provider.
- Retention - Usenet only: Set to zero to set for unlimited retention
- Maximum Size - Maximum size for a release to be grabbed in MB. Set to zero to set to unlimited. Please note that this applies globally.
- RSS Sync interval - Interval in minutes. Set to zero to disable (this will stop all automatic release grabbing) Minimum: 10 minutes Maximum: 120 minutes
- Please see How does Readarr find books? for a better understanding of how RSS Sync will help you
If Readarr has been offline for an extended period of time, Readarr will attempt to page back to find the last release it processed in an attempt to avoid missing a release. As long as your indexer supports paging and it hasn’t been too long will be able to process the releases it would have missed and avoid you needing to perform a search for the missed releases.
¶ Download Clients
Information on supported download clients can be found at the More Info (Supported) page for this section
¶ Overview
- Downloading and importing is where most people experience issues. From a high level perspective, the software needs to be able to communicate with your download client and have access to the files it downloads. There is a large variety of supported download clients and an even bigger variety of setups. This means that while there are some common setups there isn't one right setup and everyone's setup can be a little different. But there are many wrong setups.
¶ Download Client Processes
¶ Usenet Process
- Readarr will send a download request to your client, and associate it with a label or category name that you have configured in the download client settings. Examples: books, tv, series, music, etc.
- Readarr will monitor your download clients active downloads that use that category name. It monitors this via your download client's API.
- When the download is completed, Readarr will know the final file location as reported by your download client. This file location can be almost anywhere, as long as it is somewhere separate from your media folder and accessible by Readarr
- Readarr will scan that completed file location for files that Readarr can use. It will parse the file name to match it against the requested media. If it can do that, it will rename the file according to your specifications, and move it to the specified media location.
- Atomic Moves (instant moves) are enabled by default. The file system and mounts must be the same for your completed download directory and your media library. If the the atomic move fails or your setup does not support hard links and atomic moves then Readarr will fall back and copy the file then delete from the source which is IO intensive.
¶ Torrent Process
- Readarr will send a download request to your client, and associate it with a label or category name that you have configured in the download client settings. Examples: books, tv, series, music, etc.
- Readarr will monitor your download clients active downloads that use that category name. This monitoring occurs via your download client's API.
- Completed files are left in their original location to allow you to seed the file (ratio or time can be adjusted in the download client or from within Readarr under the specific download client). When files are imported to your media folder Readarr will hardlinkthe file if supported by your setup or copy if not hard links are not supported.
- Hard links are enabled by default. A hard link will allow not use any additional disk space. The file system and mounts must be the same for your completed download directory and your media library. If the hard link creation fails or your setup does not support hard links then Readarr will fall back and copy the file.
- If the "Completed Download Handling - Remove" option is enabled in Readarr's settings, Readarr will delete the original file and torrent from your client, but only if the client reports that seeding is complete and torrent is stopped.
¶ Download Clients
Click on Settings =>Download Clients`, and then click the + to add a new download client. Your download client should already be configured and running.
¶ Supported Download Clients
- A list of supported download clients is located at the More Info (Supported) page
Select the download client you wish to add, and there will be a pop-up box to enter connection details. These details are similar for most clients. Some will ask for a username or password, some will ask for whether to add new downloads in a paused/start state, etc.
¶ Usenet Client Settings
- Name - The name of the download client within Readarr
- Enable - Enable this Download Client
- Host - The URL of your download client
- Port - The port of your download client
- Use SSL - Use a secure connection with your download client. Please be aware of this common mistake.
- (Advanced Option) URL Base - Add a prefix to the url; this is commonly needed for reverse proxies.
- API Key - the API key to authenticate to your client
- Username - the username to authenticate to your client (typically not needed)
- Password- the password to authenticate to your client (typically not needed)
- Category - the category within your download client that *Arr will use. To avoid unrelated downloads showing in Activity it is strongly recommended to set a category.
- Recent Priority - download client priority for recently released media
- Older Priority - download client priority for media released not recently
- (Advanced Option) Client Priority - Priority of the download client. Round-Robin is used for clients of the same type (torrent/usenet) that have the same priority. 1 is highest priority and 50 is lowest priority
¶ Torrent Client Settings
- Name - The name of the download client within Readarr
- Enable - Enable this Download Client
- Host - The URL of your download client
- Port - The port of your download client; this is typically the webgui port
- Use SSL - Use a secure connection with your download client. Please be aware of this common mistake.
- (Advanced Option) URL Base - Add a prefix to the url; this is commonly needed for reverse proxies.
- Username - the username to authenticate to your client
- Password- the password to authenticate to your client
- Category - the category within your download client that *Arr will use. To avoid unrelated downloads showing in Activity it is strongly recommended to set a category.
- Post-Import Category - the category to set after the release is downloaded and imported. Please note that this breaks completed download handling removal.
- Recent Priority - download client priority for recently released media
- Older Priority - download client priority for media released not recently
- Initial State - Initial state for torrents (Qbittorrent Only: Forced bypasses all seed thresholds)
- (Advanced Option) Client Priority - Priority of the download client. Round-Robin is used for clients of the same type (torrent/usenet) that have the same priority. 1 is highest priority and 50 is lowest priority
¶ Torrent Client Remove Download Compatibility
- Readarr is only able to set the seed ratio/time on clients that support setting this value via their API when the torrent is added. Seed goals can be set globally in the client itself or per tracker in *Arr settings for each indexer. See the table below for client compatibility.
| Client | Ratio | Time |
|---|---|---|
| Aria2 |  |
 |
| Deluge | |
|
| Download Station | |
|
| Flood | |
|
| Hadouken | |
|
| qBittorrent | |
|
| rTorrent | |
|
| Torrent Blackhole | |
|
| Transmission | |
|
| uTorrent | |
|
| Vuze | |
|
- Transmission internally has an Idle Time check, but Readarr compares it with the seeding time if the idle limit is set on a per-torrent basis. This is done as workaround to Transmission’s api limitations.
¶ Completed Download Handling
-
Completed Download Handling is how Readarr imports media from your download client to your series folders. Many common issues are related to bad Docker paths and/or other Docker permissions issues.
-
Enable - Automatically import completed downloads from the download client
-
(Advanced Option) Remove - Remove completed downloads when finished (usenet) or stopped/complete (torrents)
¶ Remove Completed Downloads
- Readarr will send a download request to your client, and associate it with a label or category name that you have configured in the download client settings.
- Readarr will monitor your download clients active downloads that use that category name. It monitors this via your download client's API.
- When the download is completed, Readarr will know the final file location as reported by your download client. This file location can be almost anywhere, as long as it is somewhere separate from your media folder.
- Readarr will scan that completed file location for video files. It will parse the video file name to match it to an book. If it can do that, it will rename the file according to your specifications, and move it to the assigned library folder.
- Leftover files from the download will be sent to your trash or recycling.
If you download using a BitTorrent client, the process is slightly different:
- Completed files are left in their original location to allow you to seed. When files are imported to your assigned library folder Readarr will attempt to hardlinkthe file or fall back to copy (use double space) if hard links are not supported.
- If the "Completed Download Handling - Remove" option is enabled in settings, Readarr will ask the torrent client to delete the original file and torrent, but this will only occur if the client reports that seeding is complete, the torrent is in the same category (i.e. not using a post-import category), the seed goal reached is supported by Readarr, and torrent is paused (stopped).
¶ Failed Download Handling
-
Failed Download Handling is only compatible with SABnzbd and NZBGet.
-
Failed Downloading Handling does not apply to Torrents nor are there plans to add such functionality.
-
There are several components that make up the failed download handling process:
-
Check Downloader:
- Queue - Check your downloader's queue for password-protected (encrypted) releases marked as a failure
- History - Check your downloader's history for failure (e.g. not enough to repair, or extraction failed)
-
When Readarr finds a failed download it starts processing them and does a few things:
- Adds a failed event to Readarr's history
- Removes the failed download from Download Client to free space and clear downloaded files (optional)
- Starts searching for a replacement file (optional)
- Blocklisting (fka 'Blacklisting') allows automatic skipping of nzbs when they fail, this means that nzb will not be automatically downloaded by Readarr ever again (You can still force the download via a manual search).
- There are 2 advanced options (on 'Download Client' settings page) that control the behavior of failed downloading in Readarr, at this time, they are all on by default.
-
Redownload - Controls whether or not Readarr will search for the same file after a failure
-
(Advanced Option) Remove - Whether or not the download should automatically be removed from Download Client when the failure is detected
¶ Remote Path Mappings
- Remote Path Mapping acts as a dumb find Remote Path and replace with Local Path This is primarily used for either merged local/remote setups using mergerfs or similar or is used for when the application and download client are not on the same server.
- A remote path mapping is used when your download client is reporting a path for completed data either on another server or in a way that *Arr doesn't address that folder.
- Generally, a remote path map is only required if your download client is on Linux when *Arr is on Windows or vice versa. A remote path map is also possibly needed if mixing Docker and Native clients or if using a remote server.
- A remote path map is a DUMB search/replace (where it finds the REMOTE value, replace it with LOCAL value for the specified Host).
- If the error message about a bad path does not contain the REPLACED value, then the path mapping is not working as you expect. The typical solution is to add and remove the mapping.
- See TRaSH's Tutorial for additional information regarding remote path mapping
If both *Arr and your Download Client are Docker Containers it is rare a remote path map is needed. It is suggested you review the Docker Guide and/or follow TRaSH's Tutorial
¶ Import Lists
Information on supported list types can be found at the More Info (Supported) page for this section
Import lists allow you to add items to Readarr automatically from your GoodReads shelves or from other users. This has the potential to add a lot of unexpected items to your Readarr database, so please use it with care.
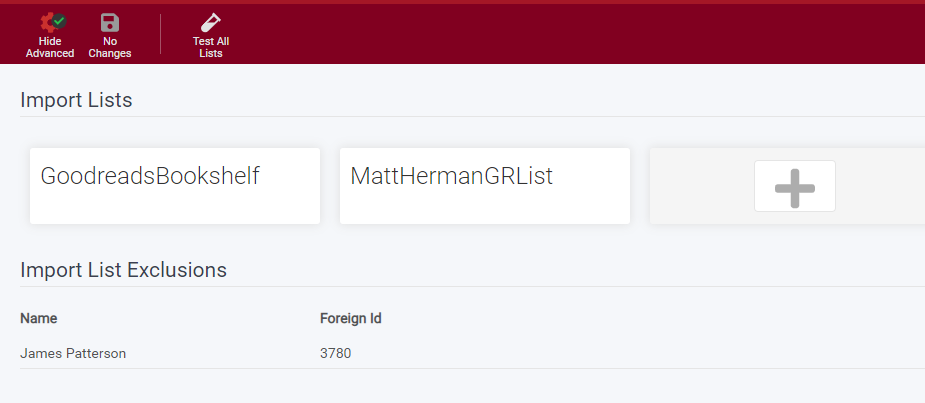
¶ Import Lists
This shows you the lists you currently have, and allows you to add new lists. Adding lists is covered below in more detail.
¶ Import List Exclusions
Anything on here has been excluded from being added by lists, and will never be added from any list. You can remove items from this by clicking on it.
¶ Adding an Import List
After clicking the +, choose what kind of list you'd like to add:
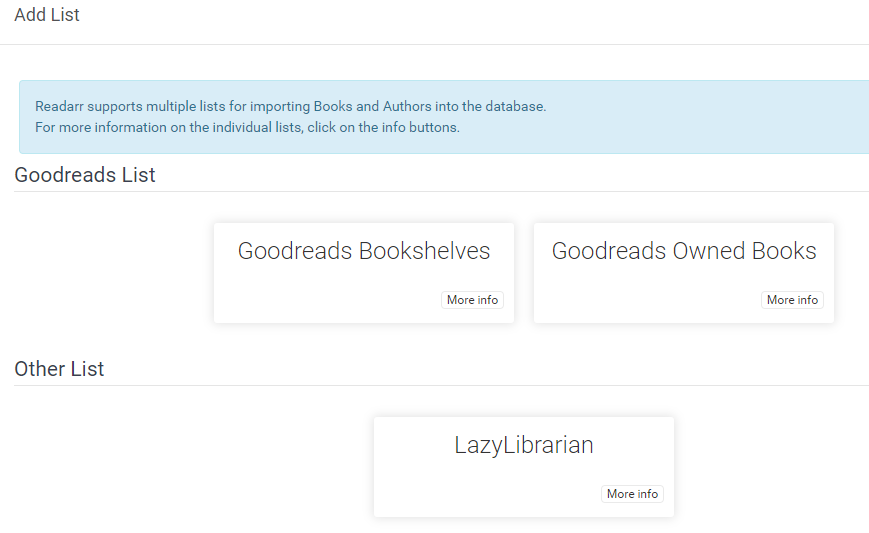
In this instance, we're going to add a GoodReads Bookshelf list.
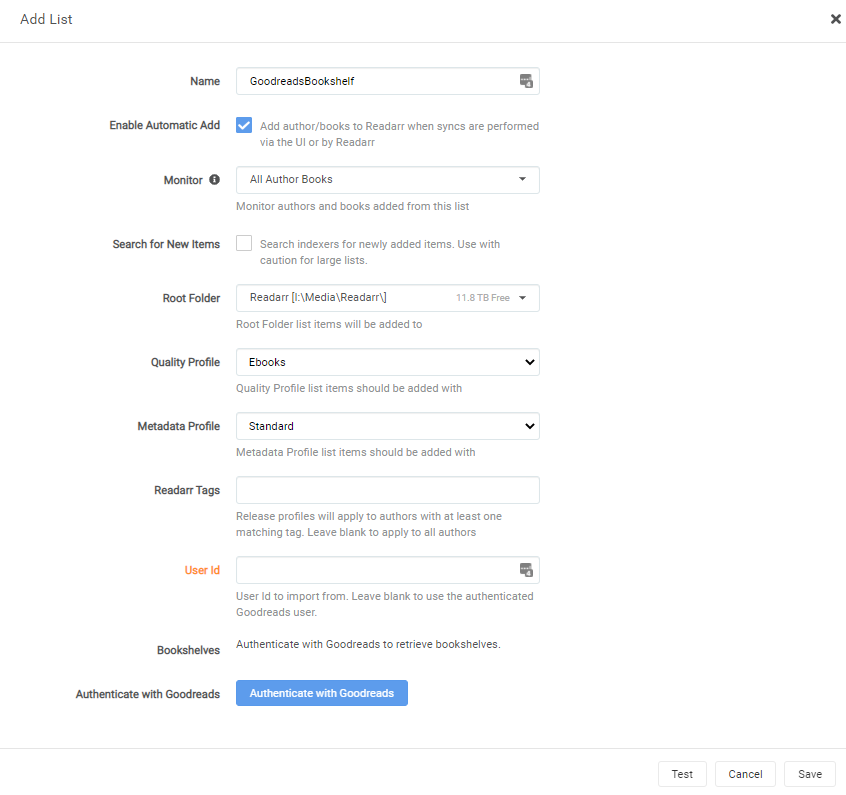
- Name - Enter a name for this list.
- Enable Automatic Add - If enabled have anything on the list automatically add to Readarr.
This is going to add all authors, and ALL BOOKS from that author, to Readarr!
- Monitor - Select your monitoring level for things added. Valid options are
None,Selected book, andAll Author Books. All books are added to Readarr, but will be monitored or unmonitored based on this selection. - Search for New Items - If enabled have Readarr initiate a search for missing monitored items when they are added from a list. If you're adding a lot of authors/monitored books, this may overload your system!
- Root Folder - Choose the root folder for authors added from this list
- Quality Profile - Choose your quality profile for authors added from this list
- Metadata Profile - Choose your metadata profile for authors added from this list
- Readarr Tags - Choose what tags apply for authors added from this list
It is highly recommended that you add a descriptive tag here. Otherwise, you will not know what list added these items to Readarr, and once they're added you can never get this information again! This info is not logged!
Lists sync by default every 24 hours, but can be triggered manually from the Settings => Tasks page. You cannot automate this process any quicker than that.
¶ Connect
Information on supported connection types can be found at the More Info (Supported) page for this section
¶ Connections
Connections are how you want Readarr to communicate with the outside world.
-
By pressing the + button you will be presented with a new window which will allow you to configure many different endpoints
-
A list of supported notifications & connections is located at the More Info (Supported) page
¶ Connection Triggers
- On Grab - Be notified when books are available for download and has been sent to a download client
- On Release Import - Be notified when books are successfully imported
- On Upgrade - Be notified when books are upgraded to a better quality
- On Download Failure - Be notified when a book download fails (usenet only)
- On Import Failure - Be notified when a book download fails to import
- On Rename - Be notified when books are renamed
- On Author Delete - Be notified when an author is deleted
- On Book Delete - Be notified when a book is deleted
- On Book File Delete - Be notified when a book file is deleted
- On Book File Delete For Upgrade - Be notified when a book file is deleted for an upgrade
- On Book Retag - Be notified when books are retagged
- On Health Issue - Be notified on health check failures
- Include Health Warnings - Be notified on health warnings in addition to errors.
¶ Metadata
Information on supported metadata consumers can be found at the More Info (Supported) page for this section
This page allows you to create/update metadata tags/covers.
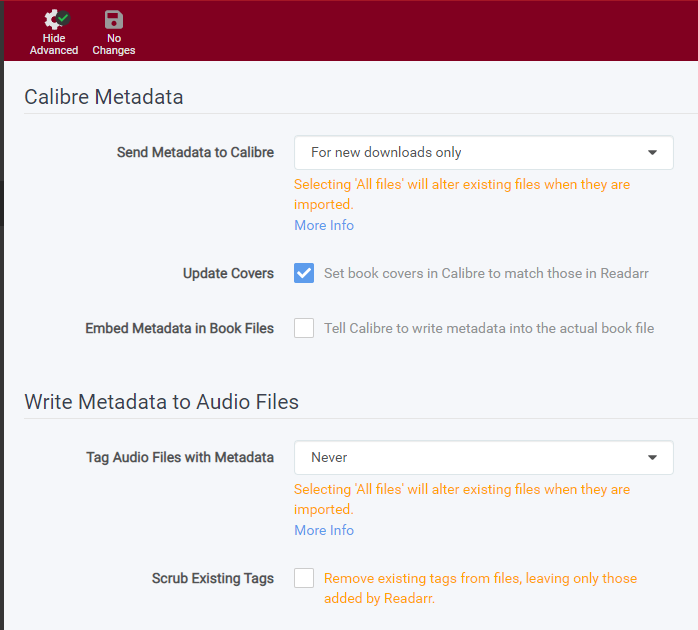
¶ Calibre Metadata
If you are using Calibre to manage your ebook collection, you will use these options to control it.
- Send Metadata to Calibre
- All files; keep in sync with GoodReads - Write tags to all files and update if GoodReads updates
- All files; initial import only - Write tags to all files once and do not update if GoodReads updates
- For new downloads only - Write tags to only new downloads when they are imported
- Update Covers - Enable to tell Calibre Content Server to use the same book covers as Readarr
- Embed Metadata in Book Files - Enable to tell Calibre Content Server to write and embed metadata into the book files.
¶ Write Metadata to Audio Files
If you are using audiobooks, you will use these options to control it.
- Tag Audio Files with Metadata
- All files; keep in sync with GoodReads - Write tags to all files and update if GoodReads updates
- All files; initial import only - Write tags to all files once and do not update if GoodReads updates
- For new downloads only - Write tags to only new downloads when they are imported
- Scrub Existing Tags - Enable to remove all tags from files except those added by Readarr
¶ Tags
-
The tag section in Readarr is used to link different aspects of Readarr.
-
Tags are particularly useful for:
- Release Profiles
- Indexers
- Import Lists
-
Tags can be used to link Release Profiles, Indexers, Import Lists and Authors/Books together.
-
For Example:
- You want a specific Author/Book to only use a specific indexer. You would create a tag and assign the Author/Book and indexer that tag.
- You want a specific Import List to only use a specific Release Profile. You would create a tag and assign the Import List and Release Profile that tag.
It is highly recommended that you add a descriptive tag to an Import List aside from what is mentioned above.
Note: Tags do not influence any "Quality Profiles", "Metadata Profiles" or any other aspect not mentioned above.
¶ General
This page is for general Readarr settings that are not covered in other sections.
¶ Host
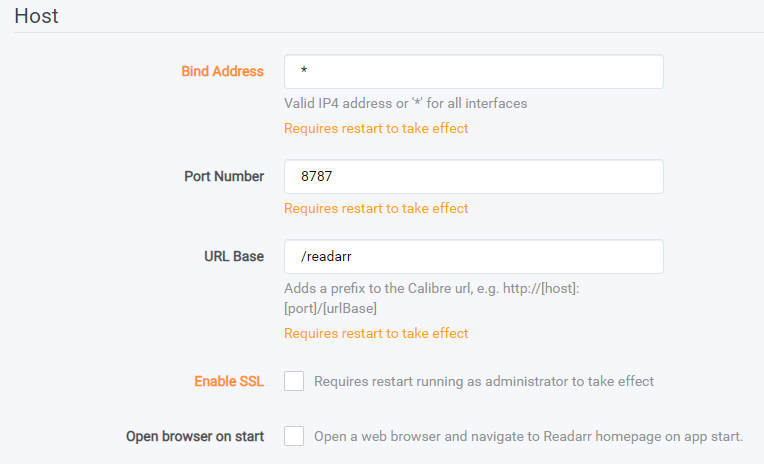
- Bind Address - Valid IP4 address or '*' for all interfaces
- 0.0.0.0 or
*- any address can connect - 127.0.0.1 or localhost - only localhost applications can connect
- Any other IP (e.g. 1.2.3.4) - only that IP (1.2.3.4) can connect
- 0.0.0.0 or
- Port Number - The port number that you are wanting to use to access the webUI for Readarr
Note: If using Docker do not touch this setting.
- URL Base - For reverse proxy support, default is empty
Note: If using a reverse proxy (example: mydomain.com/readarr) you would enter '/readarr' for URL Base.
- Enable SSL - If you have SSL credentials and would like to secure communication to and from your Readarr enable this option.
Note: Do not use this unless you know what you're doing.
¶ Security
- Authentication - How would you like to authenticate to access your Readarr instance
- None - You have no authentication to access your Readarr. Typically if you're the only user of your network, do not have anybody on your network that would care to access your Readarr or your Readarr is not exposed to the web
- Basic (Browser pop-up) - This option when accessing your Readarr will show a small pop-up allowing you to input a Username and Password
- Forms (Login Page) - This option will have a familiar looking login screen much like other websites have to allow you to log onto your Readarr
- API Key - This is how other programs would communicate or have Readarr communicate to other programs. This key if given to the wrong person with access could do all kinds of things to your library. This is why in the logs the API key is redacted
- Certificate Validation - Change how strict HTTPS certification validation is
- Enabled - Validate all HTTPS certificates (recommended)
- Disabled for Local Addresses - Validate all HTTPS certificates except those on localhost and the LAN
- Disabled - Do not validate any HTTPS certificates
¶ Proxy
-
Proxy - This option allows you to run the information your Radarr pulls and searches for through a proxy. This can be useful if you're in a country that does not allow the downloading of Torrent files
-
Use Proxy - Enable to use a Proxy
-
Proxy Type - Select your proxy type (HTTPS, Socks4, or Socks5)
-
Hostname - Enter your proxy hostname (Do not include http/https or any other protocol)
-
Port - Enter your proxy port
-
Username - Enter your proxy username if applicable
-
Password - Enter your proxy password if applicable
-
Ignored Addresses - Enter a comma-separated list of addresses that bypass the proxy
-
Bypass Proxy for Local Addresses - Check the box to bypass the proxy for local addresses.
¶ Logging
- Log level - Probably one of the most useful troubleshooting tools
- Info - This is the most basic way that Readarr gathers information this will include very minimal amount of information in the logs. This log file contains fatal, error, warn and info entries.
- Debug - Debug will include all the information that Info includes plus more information that can be useful. This log files contains fatal, error, warn, info and debug entries
- Trace - The most advance and detailed logging on Readarr, Trace will include all the information gathered by Info and Debug and more. This is the most common type of log that is going to be asked for when troubleshooting on Discord or Reddit. If you're needing help please select your log to Trace and redo the task that was giving you problems to capture the log. This log files contains fatal, error, warn, info, debug and trace entries.
¶ Analytics
- Analytics - Send anonymous usage and error information to Readarr's servers (Servarr). This includes information on your browser, which Readarr WebUI pages you use, error reporting as well as OS and runtime version. We will use this information to prioritize features and bug fixes.
¶ Updates
¶ Updates
- (Advanced Option) Branch - This is the branch of Readarr that you are running on.
- Automatic - Automatically download and install updates. You will still be able to install from System: Updates. Note: Windows Users are always automatically updated.
- Mechanism - Use Readarr built-in updater or a script
- Built-in - Use Readarr's own updater
- Script - Have Readarr run the update script
- Docker - Do not update Readarr from inside the Docker, instead pull a brand new image with the new update
- Script - Visible only when Mechanism is set to Script - Path to update script
- Update Process - Readarr will download the update file, verify its integrity and extract it to a temporary location and call the chosen method. The update process will be be run under the same user that Readarr is run under, it will need permissions to update the Readarr files as well as stop/start Readarr.
- Built-in - The built-in method will backup Readarr files and settings, stop Readarr, update the installation and Start Readarr, if your system will not handle the stopping of Readarr and will attempt to restart it automatically it may be best to use a script instead. In the event of failure the previous version of Readarr will be restarted.
- Script - The script should handle the the same as the built-in updater, if you need to handle stopping and starting services (upstart/launchd/etc) you will need to do that here.
¶ Backups
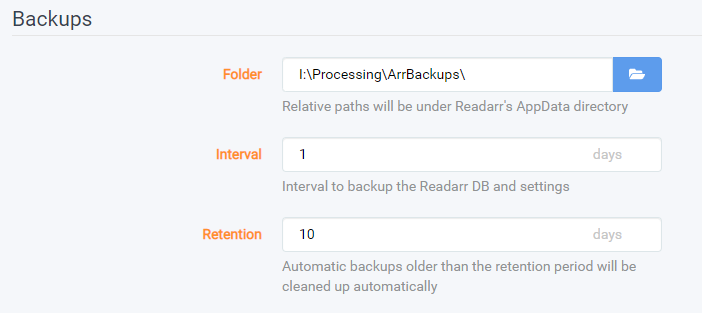
-
The backup section allows you to tell Readarr how you would like for it to handle backups
-
Folder - This allows you to select the backup location. In docker you will be limited to what you allow the container to see. Paths are relative to the appdata folder; if necessary, you can set an absolute path to backup outside of the appdata folder.
-
Interval - How often would you like Readarr to make a backup
-
Retention - How long would you like Readarr to hold on to each backup. After a new backup is made the oldest backup will be removed
By default, backups are performed every 7 days, and the last 4 are kept.
¶ UI (User Interface)
This page allows you to customize the user interface display options.
¶ Calendar
- First Day of Week - Here you can select what you think the first day of the week should be.
- Week Column Header - Here you can select the header for the columns
¶ Dates
- Short Date Format - How do you want Readarr to display short dates?
- Long Date Format - How do you want Readarr to display long format dates?
- Time Format - Do you want a 12hr or 24hr format?
- Show Relative Dates - Do you want Readarr to show relative (Today/Yesterday/etc) or absolute dates?
¶ Style

- Enable Color-Impaired Mode - Altered style to allow color-impaired users to better distinguish color coded information
¶ Language
- UI Language - Select the Language for Radarr to use within the application UI