¶ Announcement: Retirement of Readarr
We would like to announce that the Readarr project has been retired. This difficult decision was made due to a combination of factors: the project's metadata has become unusable, we no longer have the time to remake or repair it, and the community effort to transition to using Open Library as the source has stalled without much progress.
Third-party metadata mirrors exist, but as we're not involved with them at all, we cannot provide support for them. Use of them is entirely at your own risk. The most popular mirror appears to be rreading-glasses.
Without anyone to take over Readarr development, we expect it to wither away, so we still encourage you to seek alternatives to Readarr.
¶ Key Points
- Effective Immediately: The retirement takes effect immediately. Please stay tuned for any possible further communications.
- Support Window: We will provide support during a brief transition period to help with troubleshooting non metadata related issues.
- Alternative Solutions: Users are encouraged to explore and adopt any other possible solutions as alternatives to Readarr.
- Opportunities for Revival: We are open to someone taking over and revitalizing the project. If you are interested, please get in touch.
- Gratitude: We extend our deepest gratitude to all the contributors and community members who supported Readarr over the years.
Thank you for being part of the Readarr journey. For any inquiries or assistance during this transition, please contact our team.
Sincerely,
The Servarr Team
¶ Table of Contents
- Table of Contents
- Asking for Help
- Logging and Log Files
- Multiple Log Files
- Recovering from a Failed Update
- Downloads and Importing
- Testing the Download Client
- Testing a Download
- Testing an Import
- Common Problems
- You prefer one format, but it imported another format instead
- Download Client's WebUI is not enabled
- SSL in use and incorrectly configured
- Can’t see share on Windows
- Mapped network drives are not reliable
- Docker and user, group, ownership, permissions and paths
- Remote Path Mapping
- Permissions on the Library Folder
- Permissions on the Downloads Folder
- Download folder and library folder not different folders
- Incorrect category
- Packed torrents
- Repeated downloads
- Usenet download misses import
- Download client clearing items
- Download cannot be matched to a library item
- The underlying connection was closed: An unexpected error occurred on a send
- The request timed out
- Problem Not Listed
- Searches Indexers and Trackers
- Turn logging up to trace
- Testing an Indexer or Tracker
- Testing a Search
- Common Problems
- Unable to Load Search Results
- Media is Unmonitored
- Wrong categories
- Wrong results
- Query Successful - No Results returned
- Missing Results
- Certificate validation
- Hitting rate limits
- IP Ban
- Using the Jackett /all endpoint
- Using NZBHydra2 as a single entry
- Book imported with incorrect edition
- Problem Not Listed
- Errors
- Metadata API Issues
¶ Asking for Help
Do you need help? That's okay, everyone needs help sometimes. You can get real time help via chat on
But before you go there and post, be sure your request for help is the best it can be. Clearly describe the problem and briefly describe your setup, including things like your OS/distribution, version of .NET, version of Readarr, download client and its version. If you are using Docker please run through Docker Guide first as that will solve common and frequent path/permissions issues. Otherwise please have a docker compose handy. How to Generate a Docker Compose Tell us about what you've tried already, what you've looked at. Use the Logging and Log Files section to turn your logging up to trace, recreate the issue, pastebin the relevant context and include a link to it in your post. Maybe even include some screen shots to highlight the issue.
The more we know, the easier it is to help you.
¶ Logging and Log Files
It is likely beneficial to also review the Common Troubleshooting problems:
If you're asked for debug logs your logs will contain debug and if you're asked for trace logs your logs will contain trace. If the logs you are providing do not contain either then they are not the logs requested.
- Avoid sharing the entire log file unless asked.
- Don't upload logs directly to Discord or paste them as walls of text, unless requested.
- Don't share the logs as an attachment, a zip archive, or anything other than text shared via the services noted below
To provide good and useful logs for sharing:
Ensure a spammy task is NOT running such as an RSS refresh
- Turn Logging up to Trace (Settings => General => Log Level or Edit The Config File)
- Clear Logs (System => Logs => Clear Logs or Delete all the Logs in the Log Folder)
- Reproduce the Issue (Redo what is breaking things)
- Open the trace log file (readarr.trace.txt) via the UI or the log file on the filesystem and find the relevant context
- Copy a big chunk before the issue, the issue itself, and a big chunk after the issue.
- Use Gist, 0bin (Be sure to disable colorization), PrivateBin, Notifiarr PrivateBin, Hastebin, Ubuntu's Pastebin, or similar sites - excluding those noted to avoid below - to share the copied logs from above
Warnings:
- **Do not use pastebin.com as their filters have a tendency to block the logs.
- Do not use pastebin.pl as their site is frequently not accessible.
- Do not use JustPasteIt as their site does not facilitate reviewing logs.
- Do not upload your log as a file
- Do not upload and share your logs via Google Drive, Dropbox, or any other site not noted above.
- Do not archive (zip, tar (tarball), 7zip, etc.) your logs.
- Do not share console output, docker container output, or anything other than the application logs specified
Important Note:
- When using 0bin, be sure to disable colorization and do not burn after reading.
- Alternatively If you're looking for a specific entry in an old log file but aren't sure which one you can use N++. You can use the Notepad++ "Find in Files" function to search old log files as needed.
- Unix Only: Alternatively If you're looking for a specific entry in an old log file but aren't sure which one you can use grep. For example if you want to find information about the movie/show/book/song/indexer "Shooter" you can run the following command
grep -inr -C 100 -e 'Shooter' /path/to/logs/*.trace*.txtIf your Appdata Directory is in your home folder then you'd run:grep -inr -C 100 -e 'Shooter' /home/$User/.config/logs/*.trace*.txt
* The flags have the following functions
* -i: ignore case
* -n: show line number
* -r: recursively check all files in the path
* -C: provide # of lines before and after the line it is found on
* -e: the pattern to search for
¶ Standard Logs Location
The log files are located in Readarr's Appdata Directory, inside the logs/ folder. You can also access the log files from the UI at System => Logs => Files.
Note: The Logs ("Events") Table in the UI is not the same as the log files and isn't as useful. If you're asked for logs, please copy/paste from the log files and not the table.
¶ Update Logs Location
The update log files are located in Readarr's Appdata Directory, inside the UpdateLogs/ folder.
¶ Sharing Logs
The logs can be long and hard to read as part of a forum or Reddit post and they're spammy in Discord, so please use Pastebin, Hastebin, Gist, 0bin, or any other similar pastebin site. The whole file typically isn't needed, just a good amount of context from before and after the issue/error. Do not forget to wait for spammy tasks like an RSS sync or library refresh to finish.
¶ Trace/Debug Logs
You can change the log level at Settings => General => Logging. Readarr does not need to restarted for the change to take effect. This change only affects the log files, not the logging database. The latest debug/trace log files are named readarr.debug.txt and readarr.trace.txt respectively.
If you're unable to access the UI to set the logging level you can do so by editing config.xml in the AppData directory by setting the LogLevel value to Debug or Trace instead of Info.
<Config>
[...]
<LogLevel>debug</LogLevel>
[...]
</Config>
¶ Clearing Logs
You can clear log files and the logs database directly from the UI, under System => Logs => Files and System => Logs => Delete (Trash Can Icon)
¶ Multiple Log Files
Readarr uses rolling log files limited to 1MB each. The current log file is always ,readarr.txt, for the the other files readarr.0.txt is the next newest (the higher the number the older it is). This log file contains fatal, error, warn, and info entries.
When Debug log level is enabled, additional readarr.debug.txt rolling log files will be present. This log files contains fatal, error, warn, info, and debug entries. It usually covers a 40h period.
When Trace log level is enabled, additional readarr.trace.txt rolling log files will be present. This log files contains fatal, error, warn, info, debug, and trace entries. Due to trace verbosity it only covers a couple of hours at most.
¶ Recovering from a Failed Update
We do everything we can to prevent issues when upgrading, but if they do occur this will walk you through the steps to take to recover your installation.
¶ Determine the issue
- The best place to look when the application will not start after an update is to review the update logs and see if the update completed successfully. If those do not have an issue then the next step is to look at your regular application log files, before trying to start again, use Logging and Log Files to find them and increase the log level.
- The most frequently seen issue is that the system the app is installed on messed with the
/tmpdirectory and deleted critical *Arr files during the upgrade thus causing both the upgrade and rollback to fail. In this case, simply reinstall in-place over the existing borked installation.
¶ Migration Issue
- Migration errors will not be identical, but here is an example:
14-2-4 18:56:49.5|Info|MigrationLogger|\*\*\* 36: update\_with\_quality\_converters migrating \*\*\*
14-2-4 18:56:49.6|Error|MigrationLogger|SQL logic error or missing database duplicate column name: Items
While Processing: "ALTER TABLE "QualityProfiles" ADD COLUMN "Items" TEXT"
¶ Permission Issue
-
Permissions issues are due to the application being unable to access the the relevant temporary folders and/or the app binary folder. Fix the permissions so the user/group the application runs as has the appropriate access.
-
Synology users may encounter this Synology bug
Access to the path '/proc/{some number}/maps is denied -
Synology users may also encounter being out of space in
/tmpon certain NASes. You'll need to specify a different/tmppath for the app. See the SynoCommunity or other Synology support channels for help with this.
¶ Resolving the issue
In the event of a migration issue there is not much you can do immediately, if the issue is specific to you (or there are not yet any posts), please create a post on our subreddit or swing by our discord, if there are others with the same issue, then rest assured we are working on it.
Please ensure you did not try to use a database from
nightlyon the stable version. Branch hopping is ill-advised.
¶ Permissions Issues
-
Fix the permissions to ensure the user/group the application is running as can access (read and write) to both
/tmpand the installation directory of the application. -
For Synology users experiencing issues with
/proc/###/mapsstopping Sonarr or the other *Arr applications and updating should resolve this. This is an issue with the SynoCommunity package.
¶ Manually upgrading
Grab the latest release from our website.
Install the update (.exe) or extract (.zip) the contents over your existing installation and re-run Readarr as you normally would.
¶ Downloads and Importing
Downloading and importing is where most people experience issues. From a high level perspective, Readarr needs to be able to communicate with your download client and have access to the files it downloads. There is a large variety of supported download clients and an even bigger variety of setups. This means that while there are some common setups, there isn’t one right setup and everyone’s setup can be a little different.
The first step is to turn logging up to Trace, see Logging and Log Files for details on adjusting logging and searching logs. You’ll then reproduce the issue and use the trace level logs from that time frame to examine the issue. If someone is helping you, put context from before/after in a pastebin, Gist, or similar site to show them. It doesn’t need to be the whole file and it shouldn’t just be the error. You should also reproduce the issue while tasks that spam the log file aren’t running.
When you reach out for help, be sure to read asking for help so that you can provide us with the details we’ll need.
¶ Testing the Download Client
Ensure your download client(s) are running. Start by testing the download client, if it doesn’t work you’ll be able to see details in the trace level logs. You should find a URL you can put into your browser and see if it works. It could be a connection problem, which could indicate a wrong ip, hostname, port or even a firewall blocking access. It might be obvious, like an authentication problem where you’ve gotten the username, password or apikey wrong.
¶ Testing a Download
Now we’ll try a download, pick a book and do a manual search. Pick one of those files and attempt to download it. Does it get sent to the download client? Does it end up with the correct category? Does it show up in Activity? Does it end up in the trace level logs during the Check For Finished Download task which runs roughly every minute? Does it get correctly parsed during that task? Does the queued up download have a reasonable name? Since searches by are by id on some indexers/trackers, it can queue one up with a name that it can’t recognize.
¶ Testing an Import
Import issues should almost always manifest as an item in Activity with an orange icon you can hover to see the error. If they’re not showing up in Activity, this is the issue you need to focus on first so go back and figure that out. Most import errors are permissions issues, remember that needs to be able to read and write in the download folder. Sometimes, permissions in the library folder can be at fault too, so be sure to check both.
Incorrect path issues are possible too, though less common in normal setups. The key to understanding path issues is knowing that gets the path to the download from the download client, via its API. This becomes a problem in more unique use cases, like the download client running on a different system (maybe even OS!). It can also occur in a Docker setup, when volumes are not done well. A remote path map is a good solution where you don’t have control, like a seedbox setup. On a Docker setup, fixing the paths is a better option.
¶ Common Problems
Below are some common problems.
¶ You prefer one format, but it imported another format instead
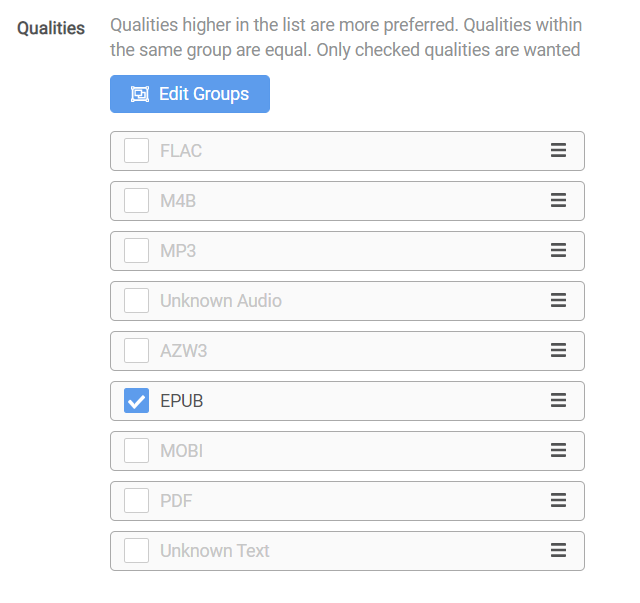
When Readarr imports, it imports in order of your priorities in your quality profile, regardless of whether they are checked or not. To resolve this issue, you need to drag your checked formats to the top of the quality list. For example, in the options below, even though only EPUB is wanted, if the download has an AZW3 in it along with the EPUB, it will get imported with priority over the EPUB, causing unwanted formats to be imported.
¶ Download Client's WebUI is not enabled
Readarr talks to you download client via it's API and accesses it via the client's webui. You must ensure the client's webui is enabled and the port it is using does not conflict with any other client ports in use or ports in use on your system.
¶ SSL in use and incorrectly configured
Ensure SSL encryption is not turned on if you're using both your instance and your download client on a local network. See the SSL FAQ entry for more information.
¶ Can’t see share on Windows
The default user for a Windows service is LocalService which typically doesn’t have access to your shares. Edit the service and set it up to run as your own user, see the FAQ entry why can’t see my files on a remote server for details.
¶ Mapped network drives are not reliable
While mapped network drives like X:\ are convenient, they aren’t as reliable as UNC paths like \\server\share and they’re also not available before login. Setup and your download client(s) so that they use UNC paths as needed. If your library is on a share, you’d make sure your root folders are using UNC paths. If your download client sends to a share, that is where you’ll need to configure UNC paths since gets the download path from the download client. It is fine to keep your mapped network drives to use yourself, just don’t use them for automation.
¶ Docker and user, group, ownership, permissions and paths
Docker adds another layer of complexity that is easy to get wrong, but still end up with a setup that functions, but has various problems. Instead of going over them here, read this wiki article for these automation software and Docker which is all about user, group, ownership, permissions and paths. It isn’t specific to any Docker system, instead it goes over things at a high level so that you can implement them in your own environment.
¶ Remote Path Mapping
If you have Readarr in Docker and the Download Client in non-Docker (or vice versa) or have the programs on different servers then you may need a remote path map.
Logs will look like
2022-02-03 14:03:54.3|Error|DownloadedBooksImportService|Import failed, path does not exist or is not accessible by Readarr: /volume3/data/torrents/audiobooks/Party of Two - Jasmine Guillory.mp3. Ensure the path exists and the user running Readarr has the correct permissions to access this file/folder
Thus /volume3/data does not exist within Readarr's container or is not accessible.
- Settings => Download Clients => Remote Path Mappings
- A remote path mapping is used when your download client is reporting a path for completed data either on another server or in a way that *Arr doesn't address that folder.
- Generally, a remote path map is only required if your download client is on Linux when *Arr is on Windows or vice versa. A remote path map is also possibly needed if mixing Docker and Native clients or if using a remote server.
- A remote path map is a DUMB search/replace (where it finds the REMOTE value, replace it with LOCAL value for the specified Host).
- If the error message about a bad path does not contain the REPLACED value, then the path mapping is not working as you expect. The typical solution is to add and remove the mapping.
- See TRaSH's Tutorial for additional information regarding remote path mapping
If both *Arr and your Download Client are Docker Containers it is rare a remote path map is needed. It is suggested you review the Docker Guide and/or follow TRaSH's Tutorial
¶ Remote Mount or Remote Sync (Syncthing)
- You need it to be syncing the whole time it is downloading. And you need that local sync destination to be able to be hard links when *Arr import, which means same file system and look like it.
- Sync at a lower, common folder that contains both incomplete and complete.
- Sync to a location that is on the same file system locally as your library and looks like it (docker and network shares make this easy to misconfigure)
- You want to sync the incomplete and complete so that when the torrent client does the move, that is reflected locally and all the files are already "there" (even if they're still downloading). Then you want to use hard links because even if it imports before its done, they'll still finish.
- This way the whole time it downloads, it is syncing, then torrent client moves to tv sub-folder and sync reflects that. That way downloads are mostly there when declared finished. And even if they're not totally done, having the hard link possible means that is still okay.
- (Optional - if applicable and/or required (e.g. remote usenet client)) Configure a custom script to run on import/download/upgrade to remove the remote file
- Alternatively a remote mount rather than a remote sync setup is significantly less complicated to configure, but typically slowly.
- Mount your remote storage with sshfs or another network file system protocol
- Ensure the user and group *Arr is configured to run as has read or write access.
- Configure a remote path map to find the REMOTE path and replace it with the LOCAL equivalent
¶ Permissions on the Library Folder
Logs will look like
2022-02-28 18:51:01.1|Error|DownloadedBooksImportService|Import failed, path does not exist or is not accessible by Readarr: /data/media/books/Jasmine Guillory/Party of Two - Jasmine Guillory.mp3. Ensure the path exists and the user running Readarr has the correct permissions to access this file/folder
Don’t forget to check permissions and ownership of the destination. It is easy to get fixated on the download’s ownership and permissions and that is usually the cause of permissions related issues, but it could be the destination as well. Check that the destination folder(s) exist. Check that a destination file doesn’t already exist or can’t be deleted or moved to recycle bin. Check that ownership and permissions allow the downloaded file to be copied, hard linked or moved. The user or group that runs as needs to be able to read and write the root folder.
-
For Windows Users this may be due to running as a service:
- the Windows Service runs under the 'Local Service' account, by default this account does not have permissions to access your user's home directory unless permissions have been assigned manually. This is particularly relevant when using download clients that are configured to download to your home directory.
- 'Local Service' also generally has very limited permissions. It's therefore advisable to install the app as a system tray application if the user can remain logged in. The option to do so is provided during the installer. See the FAQ for how to convert from a service to tray app.
-
For Synology Users refer to SynoCommunity's Permissions Article for their Packages
-
Non-Windows: If you're using an NFS mount ensure
nolockis enabled. -
If you're using an SMB mount ensure
nobrlis enabled.
¶ Permissions on the Downloads Folder
Logs will look like
2022-02-28 18:51:01.1|Error|DownloadedBooksImportService|Import failed, path does not exist or is not accessible by Readarr: /data/torrents/books/Party of Two - Jasmine Guillory.mp3. Ensure the path exists and the user running Readarr has the correct permissions to access this file/folder
Don’t forget to check permissions and ownership of the source. It is easy to get fixated on the destination's ownership and permissions and that is a possible cause of permissions related issues, but it typically is the source. Check that the source folder(s) exist. Check that ownership and permissions allow the downloaded file to be copied/hardlinked or copy+delete/moved. The user or group that runs as needs to be able to read and write the downloads folder.
-
For Windows Users this may be due to running as a service:
- the Windows Service runs under the 'Local Service' account, by default this account does not have permissions to access your user's home directory unless permissions have been assigned manually. This is particularly relevant when using download clients that are configured to download to your home directory.
- 'Local Service' also generally has very limited permissions. It's therefore advisable to install the app as a system tray application if the user can remain logged in. The option to do so is provided during the installer. See the FAQ for how to convert from a service to tray app.
-
For Synology Users refer to SynoCommunity's Permissions Article for their Packages
-
Non-Windows: If you're using an NFS mount ensure
nolockis enabled. -
If you're using an SMB mount ensure
nobrlis enabled.
¶ Download folder and library folder not different folders
- The download client should download into a folder accessible by *Arr and that is not your root/library folder; should import from that separate download folder into your Library folder.
- You should never download directly into your root folder. You also should not use your root folder as the download client's completed folder or incomplete folder.
- This will also cause a healthcheck in System as well
- Within the application, a root folder is defined as the configured media library folder. This is not the root folder of a mount. Your download client has an incomplete or complete (or is moving completed downloads) into your root (library) folder. This frequently causes issues and is not advised. To fix this change your download client so it is not placing downloads within your root folder. Note that 'placing' also includes if your download client category is set to your root folder or if NZBGet/SABnzbd have sort enabled and are sorting to your root folder. Please note that this check looks at all defined/configured root folders added not only root folders currently in use. In other words, the folder your download client downloads into or moves completed downloads to, should not be the same folder you have configured as your root/library/final media destination folder in the *Arr application.
- Configured Root Folders (aka Library folders) can be found in Settings => Media Management => Root Folders
- One example is if your downloads are going into
\data\downloadsthen you have a root folder set as\data\downloads. - It is suggested to use paths like
\data\media\for your root folder/library and\data\downloads\for your downloads.
Your download folder and your root/library folder MUST be separate
¶ Incorrect category
Readarr should be setup to use a category so that it only tries to process its own downloads. It is rare that a torrent submitted by gets added without the correct category, but it can happen. If you’re adding torrents manually and want to process them, they’ll need to have the correct category. It can be set at any time, since tries to process downloads every minute.
¶ Packed torrents
Logs will indicate errors like
No files found are eligible for import
If your torrent is packed in .rar files, you’ll need to setup extraction. We recommend Unpackerr as it does unpacking right: preventing corrupt partial imports and cleans up the unpacked files after import.
The error by also be seen if there is no valid media file in the folder.
¶ Repeated downloads
There are a few causes of repeated downloads, but one is related to the Indexer restriction in Release Profiles. Because the indexer isn’t stored with the data, any preferred word scores are zero for media in your library, but during “RSS” and search, they’ll be applied. This gets you into a loop where you download the items again and again because it looks like an upgrade, then isn’t, then shows up again and looks like an upgrade, then isn’t. Don’t restrict your release profile to an indexer.
This may also be due to the fact that the download never actually imports and then is missing from the queue, so a new download is perpetually grabbed and never imported. Please see the various other common problems and troubleshooting steps for this.
¶ Usenet download misses import
Readarr only looks at the 60 most recent downloads in SABnzbd and NZBGet, so if you keep your history this means that during large queues with import issues, downloads can be silently missed and not imported. The best way to avoid that is to keep your history clear, so that any items that still appear need investigating. You can achieve this by enabling Remove under Completed and Failed Download Handler. In NZBGet, this will move items to the hidden history which is great. Unfortunately, SABnzbd does not have a similar feature. The best you can achieve there is to use the nzb backup folder.
¶ Download client clearing items
The download client should not be responsible for removing downloads. Usenet clients should be configured so they don’t remove downloads from history. Torrent clients should be setup so they don’t remove torrents when they’re finished seeding (pause or stop instead). This is because communicates with the download client to know what to import, so if they’re removed there is nothing to be imported… even if there is a folder full of files.
For SABnzbd, this is handled with the History Retention setting.
¶ Download cannot be matched to a library item
For various reasons, releases cannot be parsed once grabbed and sent to the download client. Activity => Options => Show Unknown (this is now enabled by default in recent builds) will display all items not otherwise ignored / already imported within *Arr's download client category. These will typically need to be manually mapped and imported.
This can also occur if you have a release in your download client but that media item (movie/episode/book/song) does not exist in the application.
¶ The underlying connection was closed: An unexpected error occurred on a send
This is caused by the indexer using a SSL protocol not supported by the current .NET Version found in Readarr => System => Status.
¶ The request timed out
Readarr is getting no response from the client.
System.NET.WebException: The request timed out: ’https://example.org/api?t=caps&apikey=(removed) —> System.NET.WebException: The request timed out
2022-11-01 10:16:54.3|Warn|Newznab|Unable to connect to indexer
[v4.3.0.6671] System.Threading.Tasks.TaskCanceledException: A task was canceled.
This can also be caused by:
- improperly configured or use of a VPN
- improperly configured or use of a proxy
- local DNS issues
- local IPv6 issues - typically IPv6 is enabled, but non-functional
- the use of Privoxy and it being improperly configured
¶ Problem Not Listed
You can also review some common permissions and networking troubleshooting commands in our guide. Otherwise please discuss with the support team on discord. If this is something that may be a common problem, please suggest adding it to the wiki.
¶ Searches Indexers and Trackers
- If you use Prowlarr, then you can view the History of all queries Prowlarr received and how they were sent to the sites. Ensure that
Parametersis enabled in Prowlarr History => Options. The (i) icon provides additional details.
¶ Turn logging up to trace
The first step is to turn logging up to Trace, see Logging and Log Files for details on adjusting logging and searching logs. You’ll then reproduce the issue and use the trace level logs from that time frame to examine the issue. If someone is helping you, put context from before/after in a pastebin, Gist, or similar site to show them. It doesn’t need to be the whole file and it shouldn’t just be the error. You should also reproduce the issue while tasks that spam the log file aren’t running.
¶ Testing an Indexer or Tracker
When you test an indexer or tracker, in debug or trace logs you can find the URL used. An example of a successful test is below, you can see it query the indexer via a specific URL with specific parameters and then the response. You test this url in your browser like replacing the apikey=(removed) with the correct apikey like apikey=123. You can experiment with the parameters if you’re getting an error from the indexer or see if you have connectivity issues if it doesn’t even work. After you’ve tested in your own browser, you should test from the system is running on if you haven’t already.
¶ Testing a Search
Just like the indexer/tracker test above, when you trigger a search while at Debug or Trace level logging, you can get the URL used from the log files. While testing, it is best to use as narrow a search as possible. A manual search is good because it is specific and you can see the results in the UI while examining the logs.
In this test, you’ll be looking for obvious errors and running some simple tests. You can see the search used the url UPDATED BOOK SPECIFIC URL NEEDED - THIS IS A SONARR URL EXAMPLE https://api.nzbgeek.info/api?t=tvsearch&cat=5030,5040,5045,5080&extended=1&apikey=(removed)&offset=0&limit=100&tvdbid=354629&season=1&ep=1, which you can try yourself in a browser after replacing (removed) with your apikey for that indexer. Does it work? Do you see the expected results? Does this FAQ entry apply? In that URL, you can see that it set specific categories with cat=5030,5040,5045,5080, so if you’re not seeing expected results, this is one likely reason. You can also see that it searched by tvdbid with tvdbid=354629, so if the episode isn’t properly categorized on the indexer, it will need to be fixed. You can also see that it searches by specific season and episode with season=1 and ep=1, so if that isn’t correct on the indexer, you won’t see those results. Look at Manual Search XML Output below to see an example of a working query’s output.
- Manual Search XML Output
INDEXER SEARCH RESPONSE EXAMPLE NEEDED
Images needed
![]()
![]()
- Trace Log Snippet
Snippet of Trace Log for a Manual Search Needed
- Full Trace Log of a Search
Full section of Trace Log for a Manual Search Needed
¶ Common Problems
Below are some common problems.
¶ Unable to Load Search Results
Most likely you're using a reverse proxy and you reverse proxy timeout is set too short before *Arr has completed the search query. Increase the timeout and try again.
¶ Media is Unmonitored
The book(s) is(are) not monitored.
¶ Wrong categories
Incorrect categories is probably the most common cause of results showing in manual searches of an indexer/tracker, but not in . The indexer/tracker should show the category in the search results, which should help you figure out what is missing. If you’re using Jackett or Prowlarr, each tracker has a list of specifically supported categories. Make sure you’re using the correct ones for Categories. Many find it helpful to have the list visible in one browser window while they edit the entry in.
¶ Wrong results
Sometimes indexers will return completely unrelated results, Readarr will feed in parameters to limit the search, but the results returned are completely unrelated. Or sometimes, mostly related with a few incorrect results. The first is usually an indexer problem and you’ll be able to tell from the trace logs which is causing it. You can disable that indexer and report the problem. The other is usually categorized releases which should be reportable on the indexer/tracker.
¶ Query Successful - No Results returned
You receive a message similar to Query successful, but no results were returned from your indexer. This may be an issue with the indexer or your indexer category settings.
This is caused by your Indexer failing to return any results that are within the categories you configured for the Indexer.
¶ Missing Results
If you have results on the site you can find that are not showing in Readarr then your issue is likely one of several possibilities:
- Categories are incorrect - See Above
- An ID based searched is being done and the Indexer does not have the releases correctly mapped to that ID. This is something only your indexer can solve. They need to ensure the release is mapped to the correct applicable ids.
- Not searching how Readarr is searching; It's highly likely the terms you are searching on the indexer is not how Readarr is querying it. You can see how Readarr is querying from the Trace Logs. Text based queries will generally be in the format of
q=words%20and%20things%20herethis string is HTTP encoded and can be easily decoded using any HTML decoding/encoding tool online.
¶ Certificate validation
You’ll be connecting to most indexers/trackers via https, so you’ll need that to work properly on your system. That means your time zone and time both need to be set correctly. It also means your system certificates need to be up to date.
¶ Hitting rate limits
If you run your through a VPN or proxy, you may be competing with 10s or 100s or 1000s of other people all trying to use services like , theXEM ,and/or your indexers and trackers. Rate limiting and DDOS protection are often done by IP address and your VPN/proxy exit point is one IP address. Unless you’re in a repressive country like China, Australia or South Africa you don’t need to VPN/proxy .
¶ IP Ban
Similarly to rate limits, certain indexers - such as Nyaa - may outright ban an IP address. This is typically semi-permanent and the solution is to to get a new IP from your ISP or VPN provider.
¶ Using the Jackett /all endpoint
The Jackett /all endpoint is convenient, but that is its only benefit. Everything else is potential problems, so adding each tracker individually is required. Alternatively, you may wish to check out the Jackett & NZBHydra2 alternative Prowlarr
Even Jackett says /all should be avoided and should not be used.
Using the all endpoint has no advantages (besides reduced management overhead), only disadvantages:
- you lose control over indexer specific settings (categories, search modes, etc.)
- mixing search modes (IMDB, query, etc.) might cause low-quality results
- indexer specific categories (>= 100000) cannot be used.
- slow indexers will slow down the overall result
- total results are limited to 1000
Adding each indexer separately It allows for fine tuning of categories on a per indexer basis, which can be a problem with the /all end point if using the wrong category causes errors on some trackers. In , each indexer is limited to 1000 results if pagination is supported or 100 if not, which means as you add more and more trackers to Jackett, you’re more and more likely to clip results. Finally, if one of the trackers in /all returns an error, will disable it and now you don’t get any results.
¶ Using NZBHydra2 as a single entry
Using NZBHydra2 as a single indexer entry (i.e. 1 NZBHydra2 Entry in Readarr for many indexers in NZBHydra2) rather than multiple (i.e. many NZBHydra2 entries in Readarr for many indexers in NZBHydra2) has the same problems as noted above with Jackett's /all endpoint.
¶ Book Imported With Incorrect Edition
If a book imports with an incorrect edition, or you need to change that edition, you will need to move that book file entirely out of Readarr's root folder, then use Wanted/Manual Import to re-import it, choosing the correct edition using the drop-down at the bottom of the screen. This is the only working way to change the edition of a book after it's been imported.
¶ Problem Not Listed
You can also review some common permissions and networking troubleshooting commands in our guide. Otherwise please discuss with the support team on discord. If this is something that may be a common problem, please suggest adding it to the wiki.
¶ Errors
These are some of the common errors you may see when adding an indexer
¶ The underlying connection was closed: An unexpected error occurred on a send
This is caused by the indexer using a SSL protocol not supported by the current .NET Version found in Readarr => System => Status.
¶ The request timed out
Readarr is getting no response from the indexer.
System.NET.WebException: The request timed out: ’https://example.org/api?t=caps&apikey=(removed) —> System.NET.WebException: The request timed out
2022-11-01 10:16:54.3|Warn|Newznab|Unable to connect to indexer
[v4.3.0.6671] System.Threading.Tasks.TaskCanceledException: A task was canceled.
This can also be caused by:
- improperly configured or use of a VPN
- improperly configured or use of a proxy
- local DNS issues
- local IPv6 issues - typically IPv6 is enabled, but non-functional
- the use of Privoxy and it being improperly configured
¶ Problem Not Listed
You can also review some common permissions and networking troubleshooting commands in our guide. Otherwise please discuss with the support team on discord. If this is something that may be a common problem, please suggest adding it to the wiki.
¶ Metadata API Issues
¶ Invalid Response Received from Metadata API
This indicates that there is a problem with the metadata server. If the error is a 521 error, then it means the Cloudflare gateway has an issue reaching the metadata server. Either the metadata server as a whole is down temporarily, or that specific piece of it is down.
Sometimes you can still add an author by the author:authorID search method when you get this error.
See Readarr Status for more information.